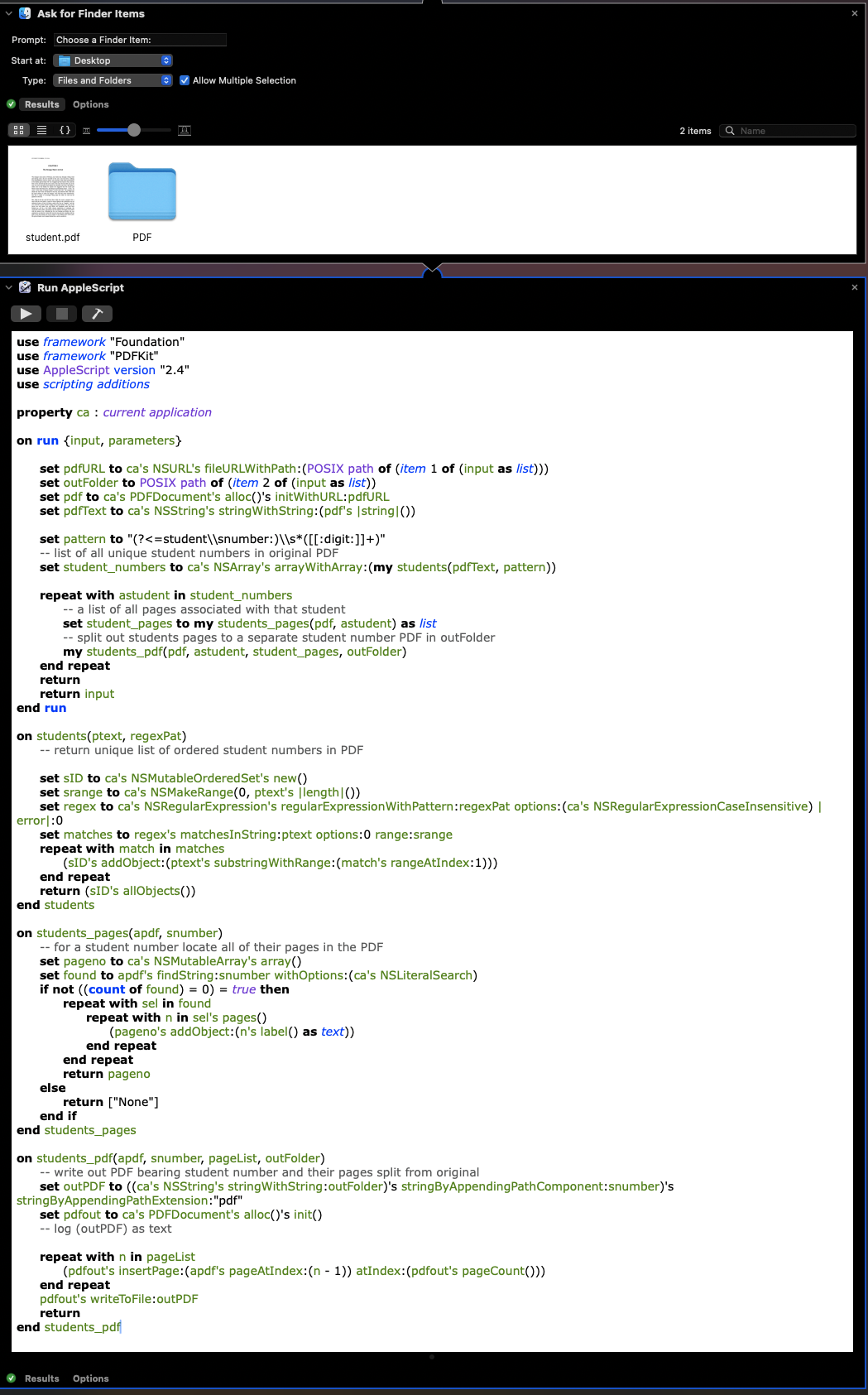
I have AppleScript/Objective-C code that has three phases:
- Get the unique, ordered student ID numbers in the PDF
- Get all sequential pages in the PDF for each student ID
- Write a PDF to a designated folder location that contains all PDF pages associated with that student ID. The PDF name will be the student ID number.
I have tested this in Apple's Script Editor and as an Automator action. Both work. My test document is a 7-page pdf with three student IDs (37313344 - 4 pages, 37313345 - 2 pages, 3711346 - 1 page) and the resulting split PDF documents reflect the same content.
The original PDF remains unchanged.
Tested on macOS Sequoia v15.0 only.
I am using two Automator actions:
- Files & Folders : Ask for Finder items
- I am choosing to ask for Files and Folders with allow multiple selections (using ⌘ key).
- Select the input PDF first, and then the Destination folder for the student's PDF. Order is important.
- Utilities : Run AppleScript
Remove the default code in the Run AppleScript action and replace it with the following:
use framework "Foundation"
use framework "PDFKit"
use AppleScript version "2.4"
use scripting additions
property ca : current application
on run {input, parameters}
set pdfURL to ca's NSURL's fileURLWithPath:(POSIX path of (item 1 of (input as list)))
set outFolder to POSIX path of (item 2 of (input as list))
set pdf to ca's PDFDocument's alloc()'s initWithURL:pdfURL
set pdfText to ca's NSString's stringWithString:(pdf's |string|())
set pattern to "(?<=student\\snumber:)\\s*([[:digit:]]+)"
-- list of all unique student numbers in original PDF
set student_numbers to ca's NSArray's arrayWithArray:(my students(pdfText, pattern))
repeat with astudent in student_numbers
-- a list of all pages associated with that student
set student_pages to my students_pages(pdf, astudent) as list
-- split out students pages to a separate student number PDF in outFolder
my students_pdf(pdf, astudent, student_pages, outFolder)
end repeat
return
return input
end run
on students(ptext, regexPat)
-- return unique list of ordered student numbers in PDF
set sID to ca's NSMutableOrderedSet's new()
set srange to ca's NSMakeRange(0, ptext's |length|())
set regex to ca's NSRegularExpression's regularExpressionWithPattern:regexPat options:(ca's NSRegularExpressionCaseInsensitive) |error|:0
set matches to regex's matchesInString:ptext options:0 range:srange
repeat with match in matches
(sID's addObject:(ptext's substringWithRange:(match's rangeAtIndex:1)))
end repeat
return (sID's allObjects())
end students
on students_pages(apdf, snumber)
-- for a student number locate all of their pages in the PDF
set pageno to ca's NSMutableArray's array()
set found to apdf's findString:snumber withOptions:(ca's NSLiteralSearch)
if not ((count of found) = 0) = true then
repeat with sel in found
repeat with n in sel's pages()
(pageno's addObject:(n's label() as text))
end repeat
end repeat
return pageno
else
return ["None"]
end if
end students_pages
on students_pdf(apdf, snumber, pageList, outFolder)
-- write out PDF bearing student number and their pages split from original
set outPDF to ((ca's NSString's stringWithString:outFolder)'s stringByAppendingPathComponent:snumber)'s stringByAppendingPathExtension:"pdf"
set pdfout to ca's PDFDocument's alloc()'s init()
-- log (outPDF) as text
repeat with n in pageList
(pdfout's insertPage:(apdf's pageAtIndex:(n - 1)) atIndex:(pdfout's pageCount()))
end repeat
pdfout's writeToFile:outPDF
return
end students_pdf