Hi 2Skip2,
Here are a couple of examples, using variations on Wayne's first formula.
The formula in H2 shows the result for column C, where every cell below C2 contains a value.
J2 and K2 contain two different formulas to handle the case in column F, containing gaps in the data.
Data in both cases was created as a Fibonacci series, the the result could be easily checked. In each case the difference between the last two numbers in the column should be the third last value in the column.
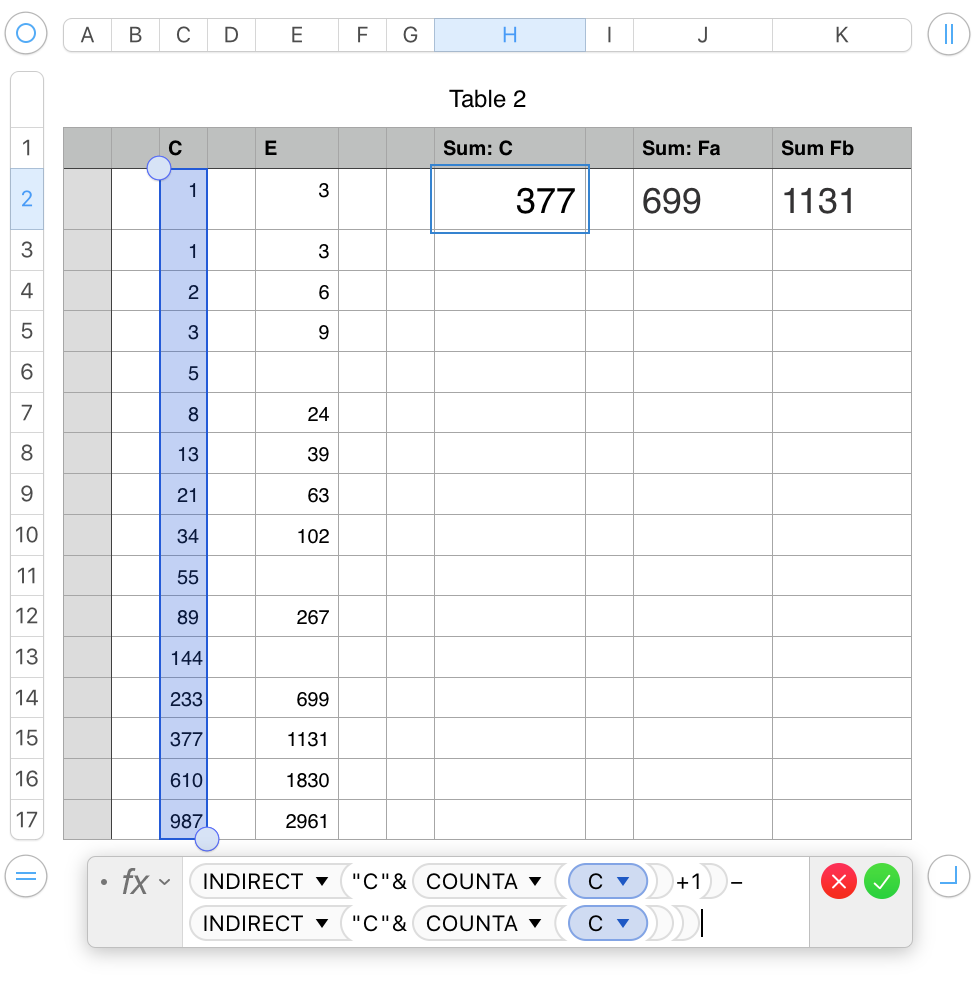
Note that the table, like yours, contains a header row, and the list of values begins in row 2.
This requires an adjustment in Wayne's formula, as his table starts the list in row 1.
Changes are shown in bold.
original: INDIRECT("C"&COUNTA(C))−INDIRECT("C"&COUNTA(C)−1)
revised: INDIRECT("C"&COUNTA(C)+1)−INDIRECT("C"&COUNTA(C))
Since either version of this formula will pay no attention to rows after the last entered value, the table can have empty rows below that last value.
J2 contains the same formula as H2, edited to reference column E instead of C:
J2: INDIRECT("E"&COUNTA($E)+1)−INDIRECT("E"&COUNTA($E))
Because there are only 13 values in the list, the first indirect is to cell C14, and the second is to the empty cell above that, giving a difference of 699.
K2 adds another count to each of the INDIRECT statements. COUNTBLANK counts the three empty cells to move the INDIRECT references down to C17 and C16.
K2: INDIRECT("E"&COUNTA($E)+COUNTBLANK(E)+1)−INDIRECT("E"&COUNTA($E)+COUNTBLANK(E))
But COUNTBLANK won't distinguish between empty cells Above the end of the list and empty cells Below the end of the list, so to use this formula, it's necessary to keep the table only as long as needed to include the last entered value.
If you're doing that, then you can use a much simpler formula:
K2: INDEX(E,ROWS(E))−INDEX(E,ROWS(E)−1)
Regards,
Barry