Hmmmm…
That turned out to be a dead end.
Pasting and copying the two 'empty' lines into TextWrangler showed only a pair of spaces and a line feed on the first line, and only a line feed on the second.
Pasting the sample showing plain text into TextWrangler showed only the plain text.
Meanwhile, I've had some out-of-thread conversations with a few others regarding this issue. The 'oddity' seems to be caused by a coding issue in the original csv file.
The (red) inverted question marks are most likely null characters (ASCII character 00000000) resulting from text encoded as UTF-16 being 'read' as if they were encoded in UTF-8. "Pure" ASCII characters are all in the range 0-127, and can be expressed with eight bits (Actually fewer). In UTF-16, each character uses 16 bits. For characters in the ASCII range, this means the first 8 of these 16 characters will all be zeros. Examples (Z and z) below.
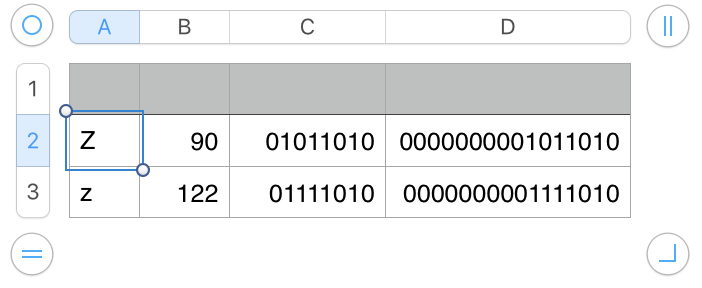
UTF-8 uses only 8 bits.
So if a text file coded as UTF-16 is read as if it were coded in UTF-8, the "Zz" string would be represented as:
00000000010110100000000001111010
from which a UTF-8 reader would extract four ASCII characters: nullZnullz with the nulls normally not visible (and taking no space), or with the null represented by a token (such as the red ¿) producing ¿Z¿n (in two colours—which won't paste here).
More detailed discussion (short article ans some useful comments) of this (and other) issues with using csv here: CSV: An Encoding Nightmare — Donat Studios
SUGGESTIONS FOR A FIX / WORKAROUND:
Tom Gewecke suggested:
I would open it in a text editor (TextEdit set to plain text, TextWrangler, BBEdit, etc) with the encoding set to utf-16 and then save it with the encoding set to utf-8.
To which I would add: …or in LibreOffice, which offers several coding systems/file formats to choose from.
Viking OSX provided the link to the article above, and this comment (detailed in the article):
Essentially, if that was an Excel exported CSV, then it is including Windows Code Page, or MacRoman characters and not UTF-8. That CSV very likely needed to be exported a certain way as explained in the article, or post-processed with the command-line utility iconv(1) before it was opened in Numbers.
The 'copy the ¿ character, paste into Find, Replace with 'nothing'' suggestion was mine, but also offered by TuringTest2 and thought of by you…
"Haven't tried it but did think about that workaround. I am more curious to know why this is occurring in the first place (i.e. why are there ASCII characters in this csv file downloaded from a trading exchange?)"
ASCII (American Standard Code for Information Interchange) is just a method of coding 128 characters, 95 of them printable, as numerical values. Ninety five was enough to cover the English alphabet (upper and lower case), the numerals, and the common punctuation marks. Later coding systems (Extended ASCII, Unicode, etc.) added more characters, but continued to use the original numbers to encode the original characters of the ASCII set. Every character in your question above is 'an ASCII character,' as is every character in this paragraph.
Perhaps you 'real' question should be "why are there UTF-16 characters in this csv file downloaded from a trading exchange?" to which the answer would be found in the linked article from Donat Studios, and the comments following the article.
Thanks for the question! It's been an interesting journey.
Regards,
Barry