If I were doing this, I would leave the data all together in one table and use filters to view subsets as needed, together with SUMIFS, COUNTIFS or Pivot Tables to extract summaries. That is usually more efficient. If I really needed the data in separate tables I would apply the filter, command-c to copy the visible cells, click once in the cell of an existing table, and command-v to paste. Quick and easier.
However, if you really want to split the data in an automated fashion into separate tables, you could do this, which is more complicated, something like this:
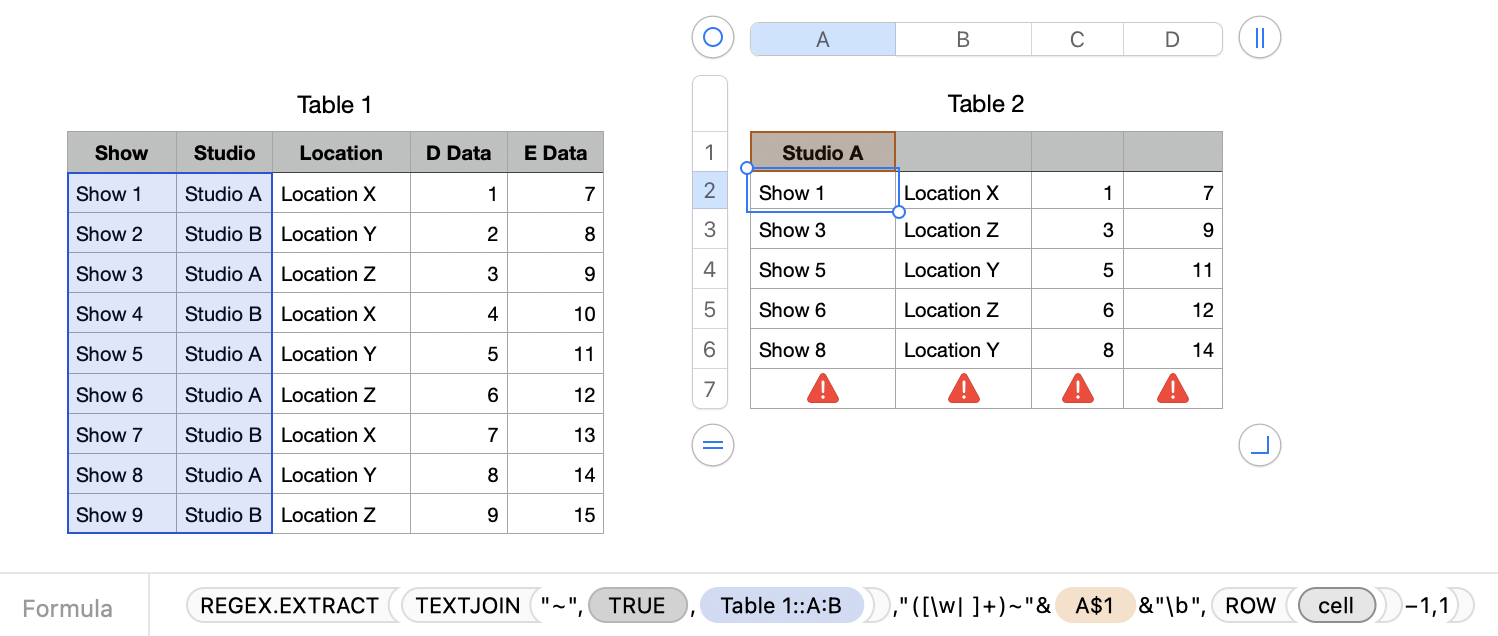
The formula in B2 of the destination table, filled down the column, is:
=REGEX.EXTRACT(TEXTJOIN("~",1,Table 1::A:B),"([\w| ]+)~"&A$1&"\b",ROW(cell)−1,1)
The formula in C2, filled down and right is:
=XLOOKUP($A2,Table 1::$A,Table 1::C,"nf")
If your region uses , as the decimal separator replace , in the formulas with ; That gives these:
=REGEX.EXTRACT(TEXTJOIN("~";1;Table 1::A:B);"([\w| ]+)~"&A$1&"\b";ROW(cell)−1;1)
=XLOOKUP($A2;Table 1::$A;Table 1::C;"nf")
This approach has the advantage of not needing extra columns, and doing the job with just two formulas.
But REGEX, even this relatively simple expression, can look intimidating. You can click the warning triangle in Column A to see what REGEX is assembled by the formula.
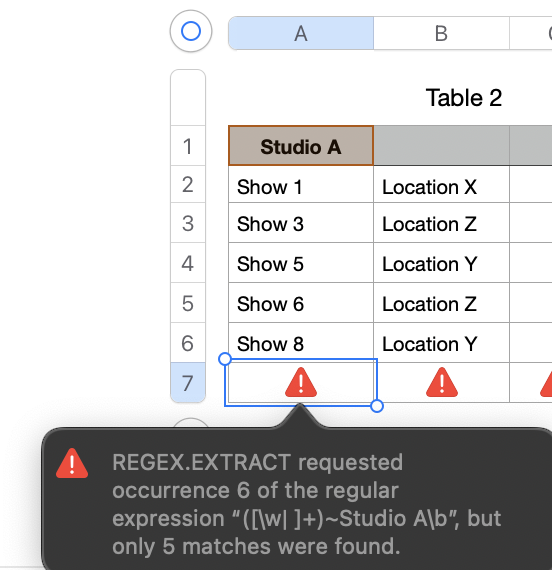
In general, though, I've founding sticking to the built-in filters and (if separate tables are really needed) good old tried-and-true copy paste can be the most reliable approach, and much quicker than it might seem.
SG